Site Reliability Engineering (SRE) : clarifications et avantages
Introduction
Au cours des dernières années, j’ai souvent évoqué le concept de Site Reliability Engineering (SRE) et comment il a révolutionné la manière dont les entreprises abordent la gestion des services informatiques. Aujourd’hui, je souhaite clarifier certains points concernant le SRE et partager mon expérience personnelle de cette approche.
Je vais également mettre en lumière les avantages que j’ai tirés de l’adoption du SRE.
Clarifications sur le SRE
Avant de plonger dans mon expérience, je voudrais clarifier certains points concernant le SRE pour ceux qui ne sont pas encore familiers avec le concept. Le SRE est une approche de gestion des services informatiques qui vise à assurer la fiabilité et la performance des systèmes tout en permettant un rythme d’innovation rapide.
Il s’appuie sur des principes clés tels que l’équilibre entre la fiabilité et l’innovation, l’utilisation d’indicateurs pour mesurer la fiabilité, l’établissement d’objectifs de niveau de service (SLO), l’automatisation et l’apprentissage tiré des échecs.
Mon expérience avec le SRE
Depuis que j’ai commencé à pratiquer le SRE il y a quelques années, j’ai constaté de nombreux avantages pour moi-même et pour mon équipe. Voici quelques-uns des avantages les plus notables que j’ai tirés de l’adoption du SRE :
-
Amélioration de la fiabilité des services : En adoptant les principes du SRE, nous avons réussi à renforcer la fiabilité de nos services. Cela s’est traduit par une expérience utilisateur améliorée, une plus grande confiance de nos clients et des équipes qui gèrent les services.
-
Meilleure communication entre les équipes : Grâce aux objectifs de niveau de service clairement définis, les attentes entre les équipes de développement et les équipes opérationnelles sont devenues plus transparentes, ce qui a facilité la collaboration et permis d’éviter les malentendus.
-
Adoption de l’automatisation : En automatisant les tâches répétitives et en réduisant le travail manuel, nous avons pu nous concentrer davantage sur les activités à forte valeur ajoutée, comme l’innovation et l’amélioration continue.
-
Apprentissage à partir des échecs : En acceptant que les erreurs et les incidents sont inévitables, nous avons adopté une approche d’apprentissage continu, ce qui nous a permis de tirer des leçons précieuses de nos échecs et d’améliorer constamment nos services.
-
Renforcement de la culture de l’innovation : En trouvant un équilibre entre la fiabilité et le rythme d’innovation, nous avons pu encourager les équipes à prendre des risques calculés et à explorer de nouvelles idées, tout en maintenant un niveau de fiabilité acceptable pour nos services.
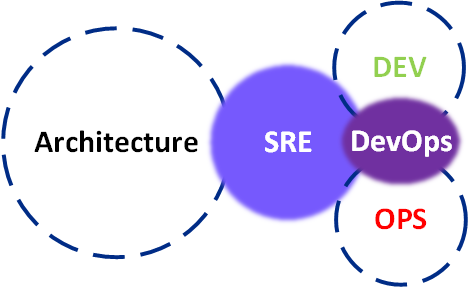
DevOps vs SRE : comparaison rapide
La SRE et le DevOps partagent des similitudes, notamment en termes de collaboration entre les équipes de développement et d’exploitation et d’accélération des cycles de développement. Cependant, ils présentent des différences clés :
La SRE repose sur des ingénieurs spécialisés en fiabilité, possédant des compétences à la fois en développement et en exploitation, ainsi qu’une compréhension approfondie de l’architecture du produit. Le DevOps se concentre sur l’efficacité du pipeline, tandis que la SRE équilibre la fiabilité et la création de fonctionnalités.
SLI et SLO
Les indicateurs de niveau de service (SLI) sont des mesures quantitatives de la performance ou de la fiabilité d’un service, tandis que les objectifs de niveau de service (SLO) définissent les attentes en matière de performance et de fiabilité basées sur les SLI. Les SLI et SLO aident les équipes SRE à évaluer la performance, à identifier les domaines d’amélioration et à assurer la satisfaction des utilisateurs. (Source : Google Cloud)
Les SLO peuvent être définis en utilisant des périodes de temps spécifiques pour mesurer la performance. Par exemple, on peut utiliser des durées comme les 30 derniers jours, les 7 derniers jours ou les 24 dernières heures pour évaluer si les objectifs sont atteints. Cela permet de mieux comprendre la performance récente et d’identifier les tendances qui peuvent nécessiter des ajustements. (Source : OCTO blog)
Eviter le chaos lors des crises
Qui n’a jamais vécu une crise en entreprise où l’on se retrouve avec 50 personnes dans un meet, dont seulement 2 essaient péniblement de résoudre le problème ?
Cette situation chaotique peut être atténuée grâce au rôle des équipes SRE. Non seulement ils sont responsables du développement et du monitoring, mais ils apprennent également de leurs erreurs et cherchent constamment à améliorer la fiabilité des systèmes.
Sachant qu’ils pourraient être réveillés en cas d’incident grave, les SRE ont tout intérêt à prioriser le monitoring pour détecter et résoudre les problèmes en amont :)
En mettant en place des processus de gestion des incidents clairs et en définissant des rôles et responsabilités précis, les SRE garantissent que seules les personnes compétentes soient impliquées dans la résolution des problèmes, évitant ainsi la confusion et les retards inutiles.
Leur expertise permet de mieux gérer les incidents et d’optimiser la performance et la fiabilité des services. Pour en savoir plus sur l’observabilité, consultez cet article : https://blog.ravindra-job.fr/cloud/observability/
Conclusion
Mes expériences en tant que Manager SRE a été extrêmement bénéfique, tant pour moi que pour mes équipes. Les SLI et SLO jouent un rôle crucial dans l’évaluation de la performance et de la fiabilité d’un service, aidant les équipes SRE à identifier les domaines d’amélioration et à garantir la satisfaction des utilisateurs.
En définissant des SLO en utilisant des périodes de temps spécifiques, les équipes peuvent mieux comprendre la performance récente et identifier les tendances qui pourraient nécessiter des ajustements. Il est essentiel de surveiller et de gérer ces métriques efficacement pour maintenir un service de haute qualité.