
Vos données avec une IA locale : Le RAG
Introduction
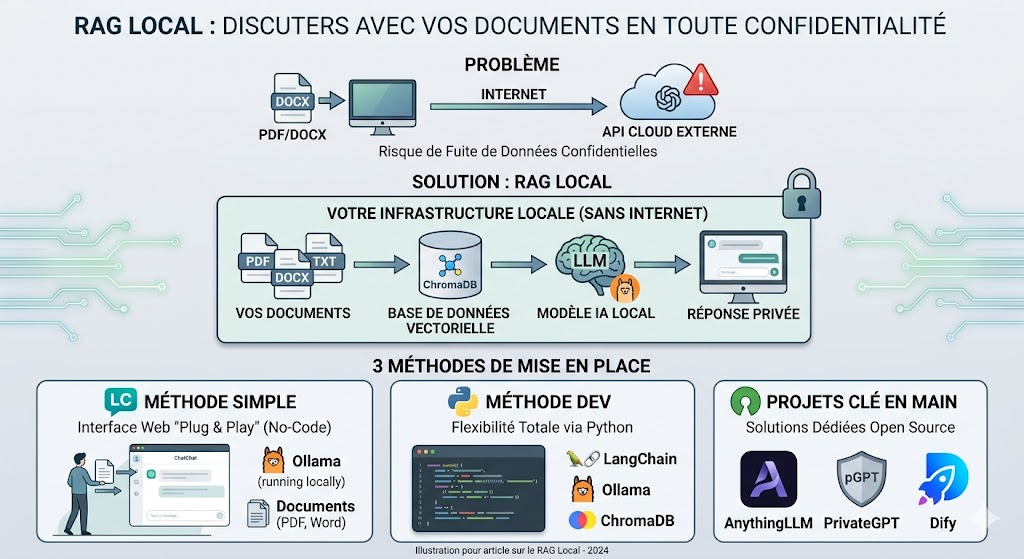
L’utilisation d’intelligences artificielles (LLM ou SLM) pour interroger sa propre base documentaire est le cas d’usage par excellence. Le problème ? Envoyer vos documents personnels ou internes d’entreprise vers des API Cloud externes pose de sérieux problèmes de confidentialiter.
La solution est le RAG (Retrieval-Augmented Generation) en local. L’idée est simple : vous permettez à une IA de piocher dans vos documents locaux pour construire sa réponse, sans que rien ne fuite sur internet.
Aujourd’hui, il existe plusieurs façons de mettre en place ce système chez soi, selon son niveau technique.
1. La méthode simple : LibreChat
Si vous ne voulez pas coder, LibreChat est l’une des meilleures solutions. Il s’agit d’une interface web unifiée (similaire à ChatGPT) que vous hébergez vous-même.
LibreChat intègre nativement une fonctionnalité de RAG. Il vous suffit de glisser-déposer vos fichiers (PDF, Word, TXT) directement dans la fenêtre de discussion. En coulisse, LibreChat va découper le document et utiliser le modèle de votre choix (que vous pouvez faire tourner localement via Ollama) pour lire le document et vous répondre. C’est l’approche la plus accessible (“plug and play”) pour monsieur et madame Tout-le-monde.
2. La méthode “Dev” : Le faire en Python
Si vous avez des besoins spécifiques ou que vous souhaitez intégrer le RAG dans une application maison, le Python reste le standard de l’industrie. On utilise généralement une stack composée de :
- Ollama : Pour faire tourner le modèle IA localement.
- ChromaDB : Une base de données vectorielle.
- LangChain ou LlamaIndex : Les frameworks d’orchestration.
Voici à quoi ressemble le cœur d’un pipeline RAG en Python :
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
# Chargement du document et vectorisation
loader = PyPDFLoader("document_secret.pdf")
docs = loader.load_and_split()
vector_db = Chroma.from_documents(docs, HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2"))
# Interrogation avec Ollama local
qa_chain = RetrievalQA.from_chain_type(llm=Ollama(model="llama3"), chain_type="stuff", retriever=vector_db.as_retriever())
print(qa_chain.run("Quels sont les budgets alloués ?"))
Le Python offre une flexibilité totale, mais demande de gérer l’ingestion, le nettoyage des données et l’infrastructure.
3. Les projets “Clé en main” Open Source
Si LibreChat est trop généraliste et que le Python est trop chronophage, il existe d’excellents projets Open Source dédiés exclusivement à la création de bases de connaissances RAG. En voici 3 incontournables :
- AnythingLLM : Une application de bureau ou serveur redoutable d’efficacité. Elle permet de créer des espaces de travail cloisonnés (workspaces) avec différents documents, et de se connecter facilement à des modèles locaux. C’est le meilleur compromis entre puissance et simplicité.
- PrivateGPT : Un projet très populaire conçu pour offrir une API de RAG prête à l’emploi et une interface minimaliste, assurant une exécution 100% locale sans fuite de données.
- Dify : Plus orienté “workflow” et MLOps, Dify permet de construire visuellement son pipeline RAG et ses agents de manière modulaire. Parfait pour les équipes qui veulent concevoir des chatbots d’entreprise.
Conclusion
Faire parler une IA avec ses propres documents n’est plus un parcours du combattant réservé aux ingénieurs Cloud. Que vous cherchiez la simplicité absolue avec LibreChat, la bidouille Python via LangChain, ou la force d’une solution packagée comme AnythingLLM, vous avez de quoi monter un RAG robuste directement sur votre machine. Fini les fuites de données vers l’extérieur : gardez le contrôle de votre savoir !
Sources
- [1] LibreChat : Interface Chat unifiée avec support RAG.
- [2] AnythingLLM : Solution RAG clé en main pour entreprise.
- [3] PrivateGPT : Intégration RAG 100% locale.
Si vous voulez plus d’information sur l’infrastructure vous pouvez voir l’ repo à ce sujet : https://github.com/ravindrajob/InfraAtHome


