Chaos Testing: Exercice de résilience dans le Cloud
Introduction
Le Chaos Testing, ou Chaos Engineering, est une discipline d’ingénierie qui vise à révéler les problèmes de fiabilité et de résilience dans les systèmes informatiques. Inspiré par les Principes du Chaos, il implique la création intentionnelle de perturbations dans les systèmes pour identifier et corriger les faiblesses avant qu’elles ne causent des problèmes majeurs 1. Dans cet article, nous explorerons l’importance du Chaos Testing dans le Cloud, en nous concentrant sur Azure Chaos Studio et les méthodes de déploiement Canary et Blue-Green.
CLOUD Azure
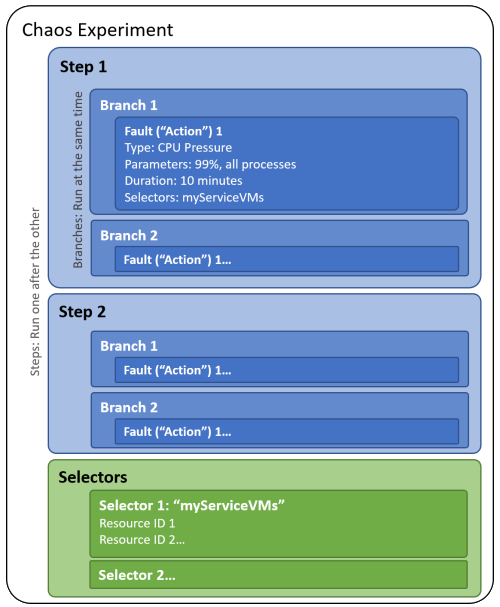
Azure développe actuellement un service appelé Azure Chaos Studio. Ce service permet aux utilisateurs d’effectuer des tests de chaos sur leurs applications et infrastructures dans Azure 2. Il offre des outils pour injecter intentionnellement des défaillances dans les systèmes pour tester leur résilience et leur fiabilité.

CLOUD Google
Google Cloud Platform (GCP) propose également des outils pour le Chaos Testing. Par exemple, GCP propose un outil open-source appelé “Cloud Operations Sandbox” 3. Il s’agit d’un environnement de démonstration qui aide les utilisateurs à se familiariser avec les services cloud de Google.
Cloud Operations Sandbox fournit une boutique de démonstration de commerce électronique. Les utilisateurs peuvent simuler des défaillances dans cette boutique pour tester la résilience de leurs applications. Par exemple, on pourrait simuler une panne de réseau pour voir comment l’application gère ce genre de problèmes. Cela permet d’identifier les points faibles et de travailler à leur résolution pour améliorer la résilience et la fiabilité des systèmes.
Pour le déploiement de l’environnement de démonstration de Google Cloud Operations Sandbox pour le Monkey Testing, vous pouvez suivre les étapes suivantes :
Cloner le dépôt
git clone https://github.com/GoogleCloudPlatform/cloud-ops-sandbox
Authentifier avec Google Cloud
gcloud auth application-default login
Créer la sandbox
cd cloud-ops-sandbox/provisioning
./sandboxctl create -p PROJECT_ID
Méthodes de déploiement
Pour bien assuré sa résilience au moment du Chaos, il est important de comprendre certaines méthodes de déploiement courantes qui peuvent servir de prérequis. Ces méthodes de déploiement, telles que le Canary Testing et le Blue-Green Deployment, sont essentielles pour assurer une transition en douceur vers de nouvelles versions de logiciels tout en minimisant l’impact sur les utilisateurs finaux.
Elles offrent également un environnement contrôlé pour l’application des principes du Chaos Testing, permettant ainsi une évaluation plus précise et plus sûre de la résilience et de la fiabilité des systèmes.
Canary Testing
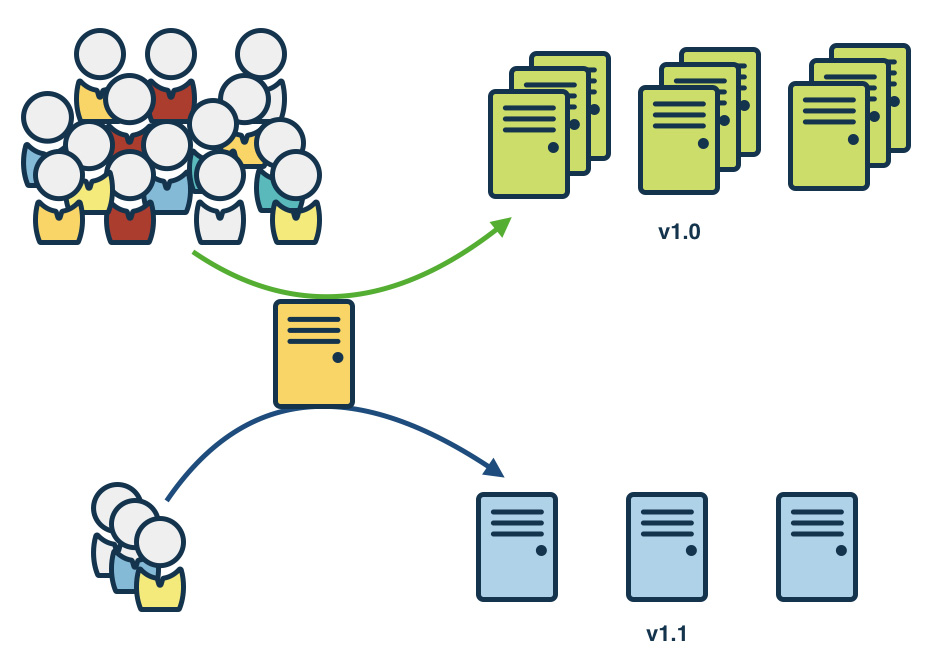
Le Canary Testing est une méthode de déploiement qui consiste à déployer une nouvelle version d’une application à un sous-ensemble d’utilisateurs pour tester son efficacité et sa fiabilité 4. Cette méthode est utile pour identifier et résoudre les problèmes avant de déployer la nouvelle version à tous les utilisateurs.
Blue-Green Deployment
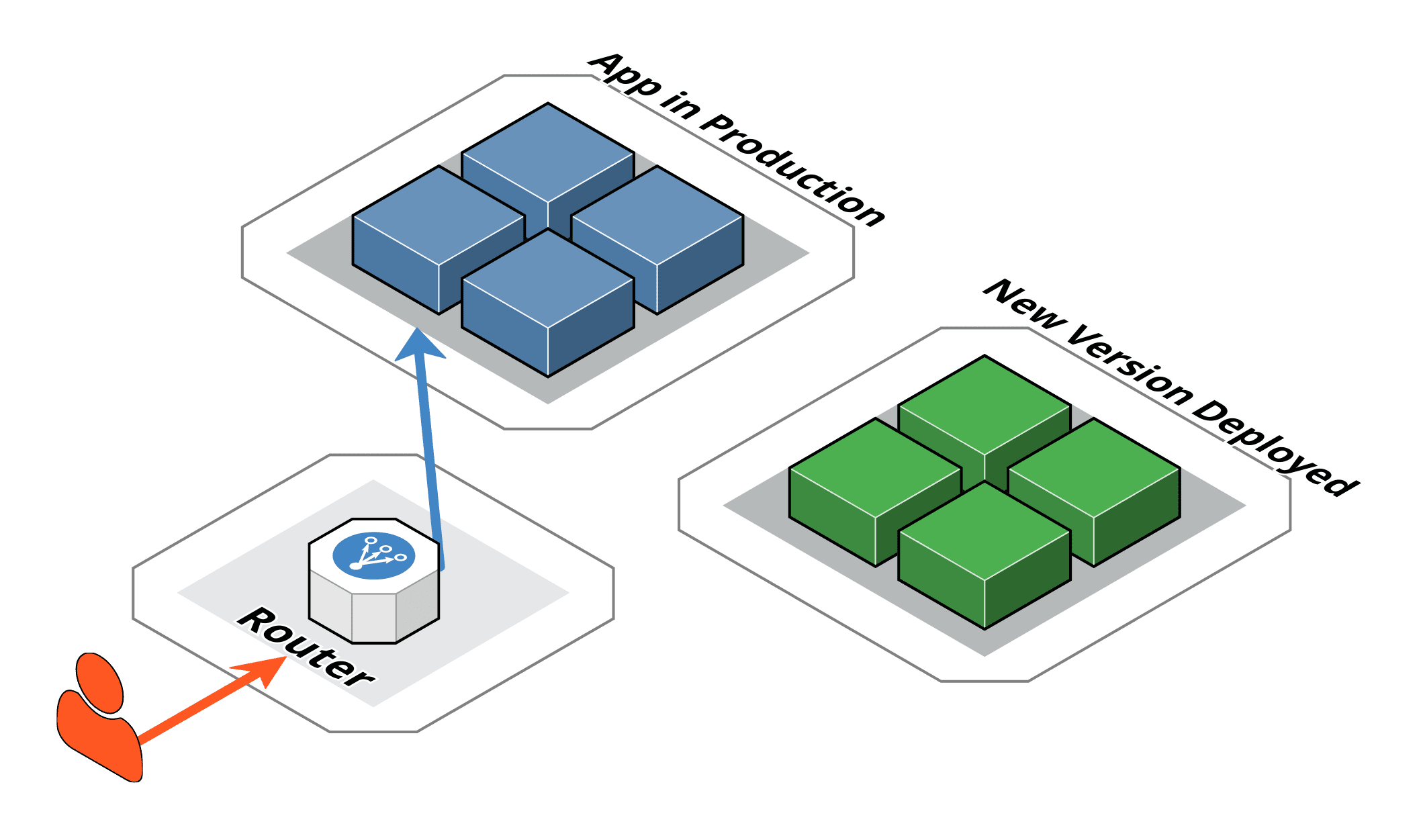
Le déploiement Blue-Green est une autre méthode de déploiement qui implique d’avoir deux environnements de production, appelés Blue et Green. Les nouvelles versions de l’application sont déployées dans l’environnement Green, et une fois que la nouvelle version a été testée et vérifiée, le trafic est basculé de Blue à Green 5.
Conclusion
Le Chaos Testing est un outil indispensable pour plusieurs raisons. Il permet de détecter des SPOF (Single Point of Failure), qui sont des éléments d’un système dont la défaillance entraînerait l’arrêt de l’ensemble du système. Le Chaos Testing permet également de corriger des failles non anticipées en simulant des conditions imprévues pour voir comment le système réagit. De plus, il offre la possibilité de prouver la résilience d’un système en le testant dans des conditions extrêmes. En d’autres termes, le Chaos Testing ne se contente pas de révéler les faiblesses, il aide également à renforcer la confiance dans la capacité du système à gérer les perturbations et à garantir une performance optimale. C’est une démarche proactive pour assurer la fiabilité et la résilience des systèmes informatiques, en particulier dans le Cloud.
UPDATE: sept 2023
Si vous voulez plus d’information sur l’infrastructure vous pouvez voir mon repo à ce sujet : https://github.com/ravindrajob/InfraAtHome